SU-8 3035 Spincurve Analysis
spincurves.Rmdintroduction
For my microfluidic chips, channel heights in the range of 20-30 um
are desired. To obtain these heights during the photolithography
process, a photoresist with suitable viscosity is required. 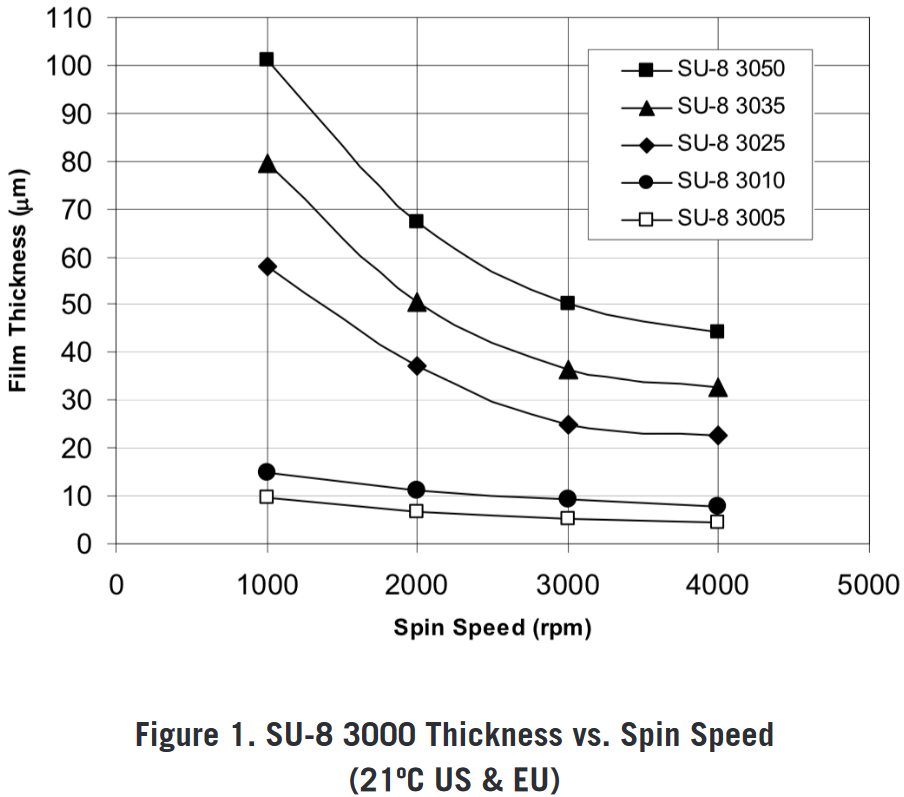
These are the spin curves for the SU-8 3000 series (“SU-8 3000 for Microstructure Fabrication Kayaku Advanced Materials. Kayaku Advanced Materials, Inc.” n.d.). It seems like SU-8 3035 can yield thicknesses in the desired range (extrapolating for higher RPMs, and from the experience that at 6000 RPM 30 um thickness can be achieved with SU-8 3050). Therefore, 115.2 g SU-8 3050 was mixed with 1.42 g of thinner solution, in order to obtain a custom dilution that mimics the behaviour of SU-8 3035. In the following, SU-8 3035 refers to this custom dilution.
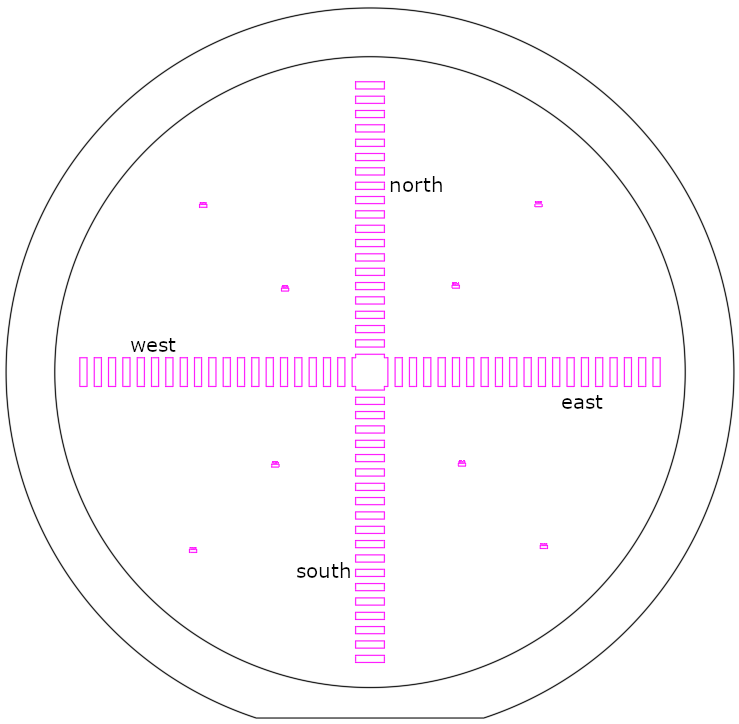
After preparation of SU-8 3035, a spin curve analysis was conducted to characterize the relation between spin speed and film thickness of the custom photoresist. To that end, a cross pattern (see image) was exposed on cleaned and re-used silicon wafers, after spin-coating SU-8 3035 at 3000, 4000, and 5000 RPM, respectively. For each of these RPM, three chips were prepared: two chips using a spin duration of 30s (to have duplicate measurements), and one chip using a spin duration of 60 s. Therefore, in total, nine wafers were prepared.
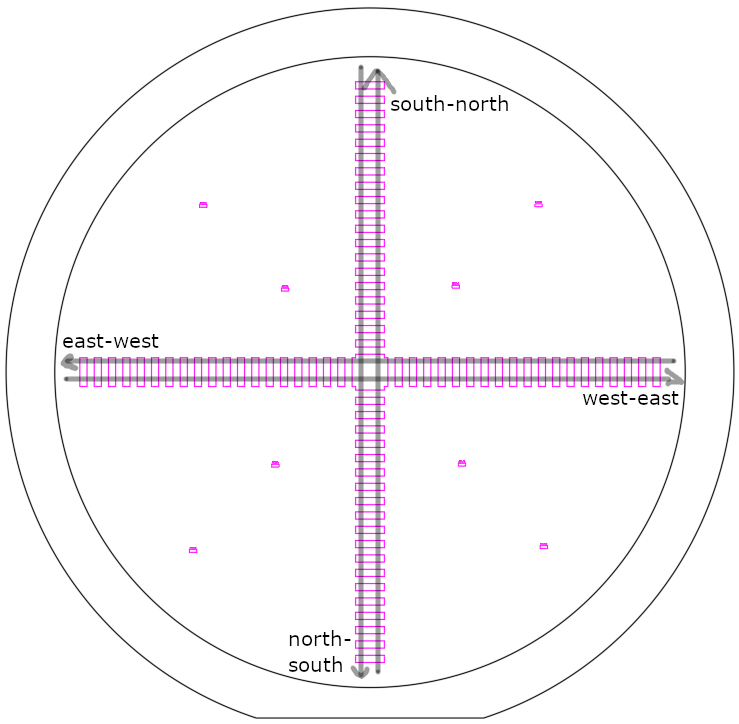
After photolithography, the resulting height profiles were measured using a Dektak profilometer. Unfortunately, when measuring over long distances with this machine, measurements are drifting away from the reference level quite significantly, which necessitates a correction before data evalutation. Therefore, the cross structure exposed on the wafer includes repeated gaps in order to pick up the zero-level along the entire wafer.
These are the wafer ids corresponding to a certain combination of spin time and spin speed:
| spin time / RPM | 3000 | 4000 | 5000 |
|---|---|---|---|
| 30 s | job9945, job9946 | job9947, job9948 | job9949, job9950 |
| 60 s | job10055 | job10053 | job10054 |
For each wafer, four traces were measured: top-to-bottom, left-to-right, bottom-to-top, and right-to-left (see figure). This results in duplicate measurements for all the structures.
In this vignette, the post-processing and drift correction of the Dektak data will be carried out. This includes:
- reading in CSV files,
- recognition of the reference level segments,
- drift correction,
- averaging of duplicate measurements,
- interpolation of height profiles between the gaps in the structure.
library(picoinjector)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(tibble)
library(readr)
library(stringr)
library(ggplot2)
# library(tidyr)data loading
Get file names:
files <- list.files("data/spincurve_csv/", full.names = TRUE)
head(files)
#> [1] "data/spincurve_csv//00_job9945_eastwest.csv"
#> [2] "data/spincurve_csv//01_job9945_northsouth.csv"
#> [3] "data/spincurve_csv//01_job9945_westeast.csv"
#> [4] "data/spincurve_csv//02_job9946_southnorth.csv"
#> [5] "data/spincurve_csv//03_job9945_southnorth.csv"
#> [6] "data/spincurve_csv//03_job9950_northsouth.csv"Read in all the csv files and concatenate them into a single tibble dataframe:
results <- tibble()
for (f in files) {
d <- read_csv(f, skip = 19, show_col_types = FALSE, col_names = c("position", "height")) %>%
select(position, height) %>%
mutate(id = basename(f)) # add the wafer id
results <- bind_rows(results, d)
}
results
#> # A tibble: 2,815,001 × 3
#> position height id
#> <dbl> <dbl> <chr>
#> 1 0 1.85 00_job9945_eastwest.csv
#> 2 0.5 1.22 00_job9945_eastwest.csv
#> 3 1 0.59 00_job9945_eastwest.csv
#> 4 1.5 0 00_job9945_eastwest.csv
#> 5 2 -0.51 00_job9945_eastwest.csv
#> 6 2.5 -0.95 00_job9945_eastwest.csv
#> 7 3 -1.32 00_job9945_eastwest.csv
#> 8 3.5 -1.63 00_job9945_eastwest.csv
#> 9 4 -1.88 00_job9945_eastwest.csv
#> 10 4.5 -2.08 00_job9945_eastwest.csv
#> # … with 2,814,991 more rowsAdd information about spin speed and duration:
# table relating wafer id with RPM
rpm <- c(job9945 = 3000, job9946 = 3000, job9947 = 4000, job9948 = 4000,
job9949 = 5000, job9950 = 5000, job10053 = 4000, job10054 = 5000, job10055 = 3000)
# table relating wafer id with seconds at max RPM
spinTime <- c(job9945 = 30, job9946 = 30, job9947 = 30, job9948 = 30,
job9949 = 30, job9950 = 30, job10053 = 60, job10054 = 60, job10055 = 60)
results <- results %>%
mutate(wafer = str_extract(id, "job\\d+"),
direction = str_extract(id, "[a-z]+\\.") %>%
str_remove("\\."),
orientation = case_when(direction %in% c("eastwest", "westeast") ~ "horizontal",
TRUE ~ "vertical"),
rpm = rpm[wafer],
spintime = spinTime[wafer]) %>%
# order rows by wafer, direction and position
group_by(rpm, spintime, direction) %>%
arrange(rpm, spintime, .by_group = TRUE) %>%
ungroup()
results
#> # A tibble: 2,815,001 × 8
#> position height id wafer direc…¹ orien…² rpm spint…³
#> <dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 0 1.85 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 2 0.5 1.22 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 3 1 0.59 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 4 1.5 0 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 5 2 -0.51 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 6 2.5 -0.95 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 7 3 -1.32 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 8 3.5 -1.63 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 9 4 -1.88 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> 10 4.5 -2.08 00_job9945_eastwest.csv job9945 eastwe… horizo… 3000 30
#> # … with 2,814,991 more rows, and abbreviated variable names ¹direction,
#> # ²orientation, ³spintimeThe raw data looks like this:
profile <- results %>%
# filter for single trace
filter(id == "00_job9945_eastwest.csv")
plot_heightprofile(profile)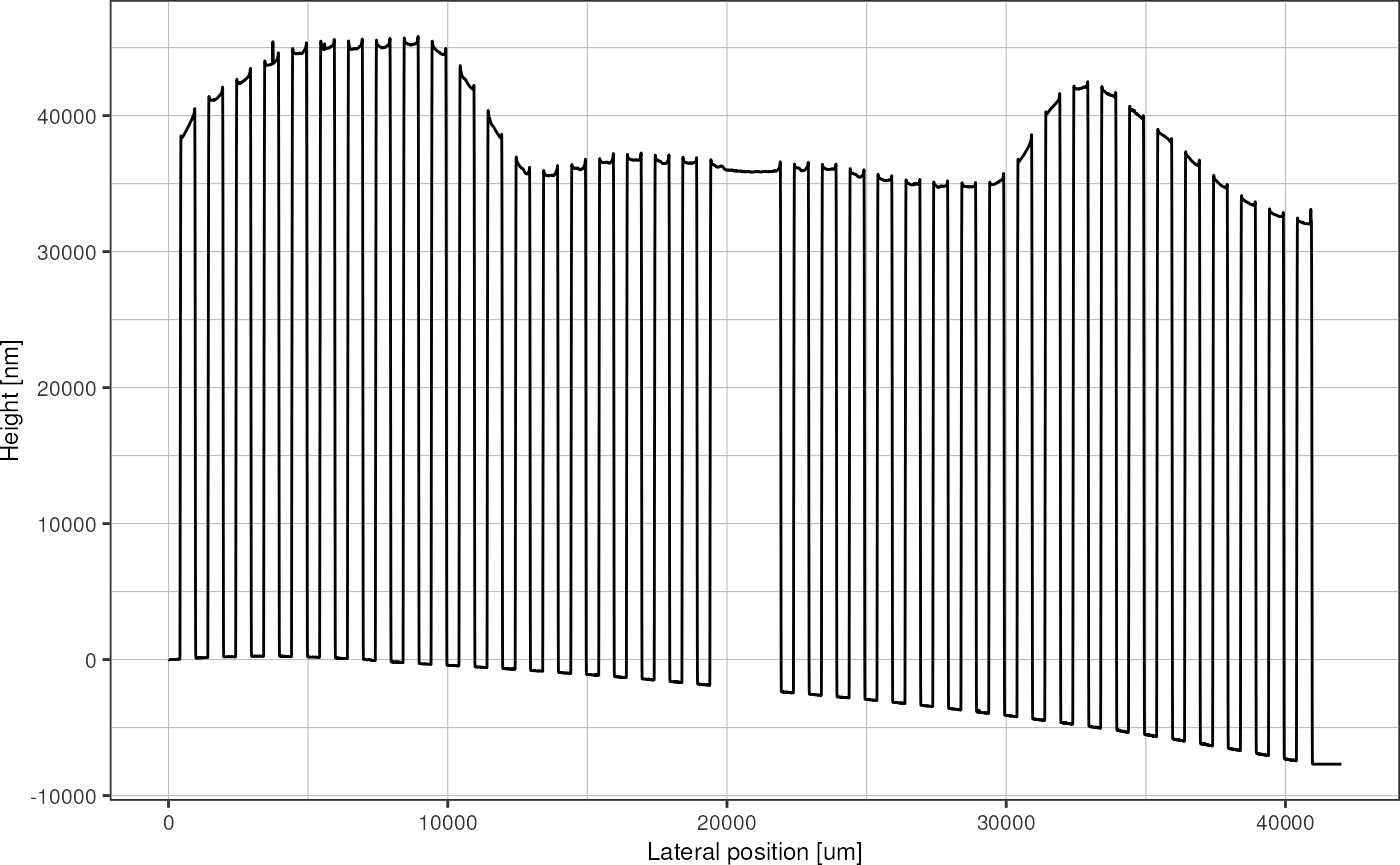
baseline correction
Now I use the geometrical information of my design to determine peaks and valleys in the trace. First, I find the positions (x coordinate) of the leftmost and rightmost structure using the slope of the graph, and then I rescale everything so that it spans the known width of 40.5 mm that was written on the wafer. The rescaling is necessary in case the trace was not perfectly aligned with the structure, i.e. slightly diagonal and therefore a little bit longer.
profile %>%
filter(position < 1000) %>% # zoom at left-most peak
plot_heightprofile()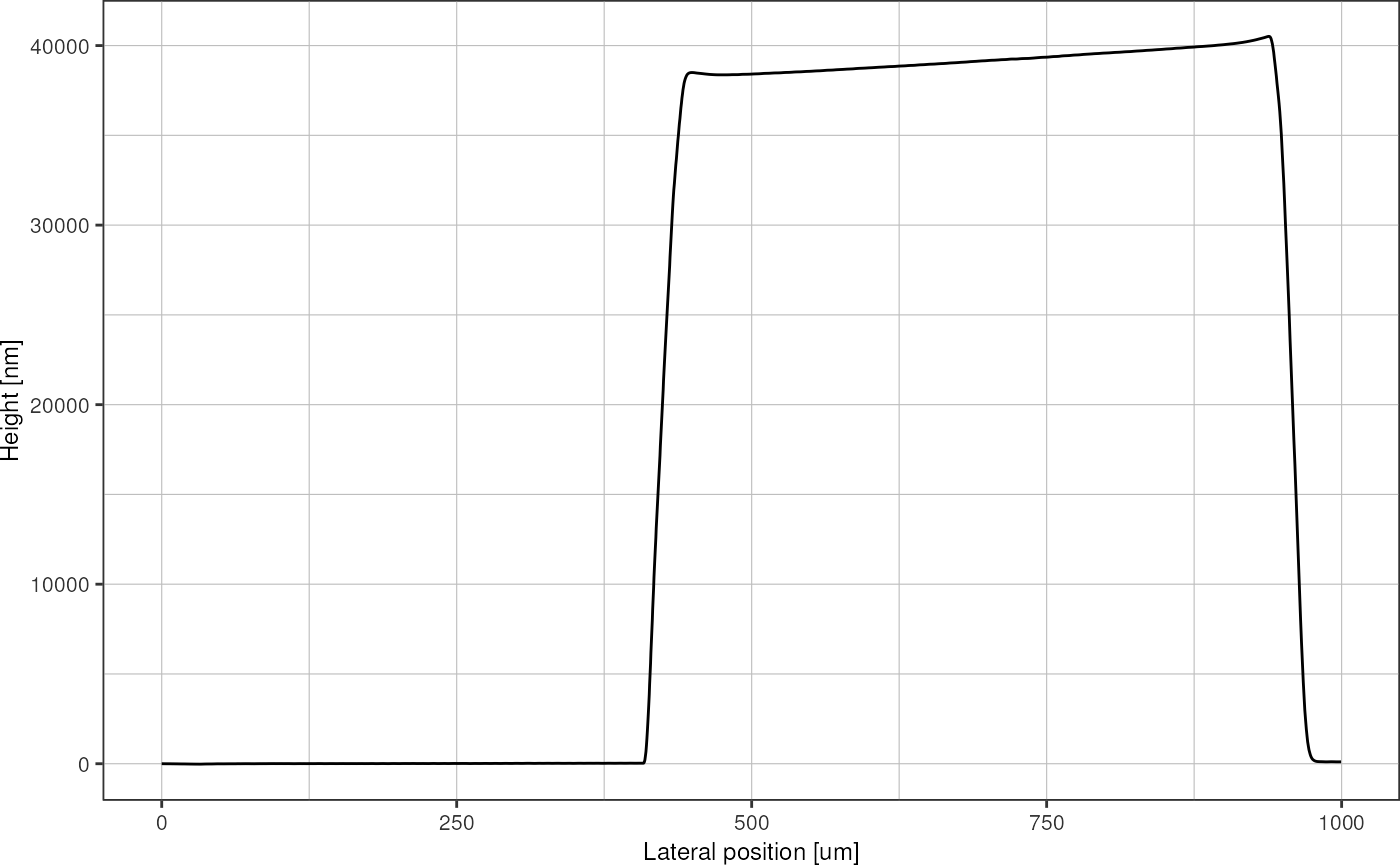
To find the x coordinate were the first structure begins, I calculate the first derivative of the height profile (lagged differences) in order to identify regions with large slope. The first derivative of above graph then looks like this:
# lagged differences parameters
lag <- 10
dif <- 1
offset <- dif * lag
# calculate derivative
derivative <- tibble(
"d_height" = diff(profile$height, lag = lag, differences = dif) / diff(profile$position, lag = lag, differences = dif),
# adjust dimension of x axis (lagging difference removes the first l elements):
"position" = profile$position[(offset+1):length(profile$position)]
)
derivative %>%
filter(position < 1000) %>% # zoom to first structure
ggplot(aes(x = position, y = d_height)) +
geom_line() +
labs(title = "Derivative of height profile",
subtitle = paste("Lag =", lag, ", difference order =", dif),
x = "Lateral position [um]",
y = "Lagged difference magnitude") +
theme_pretty()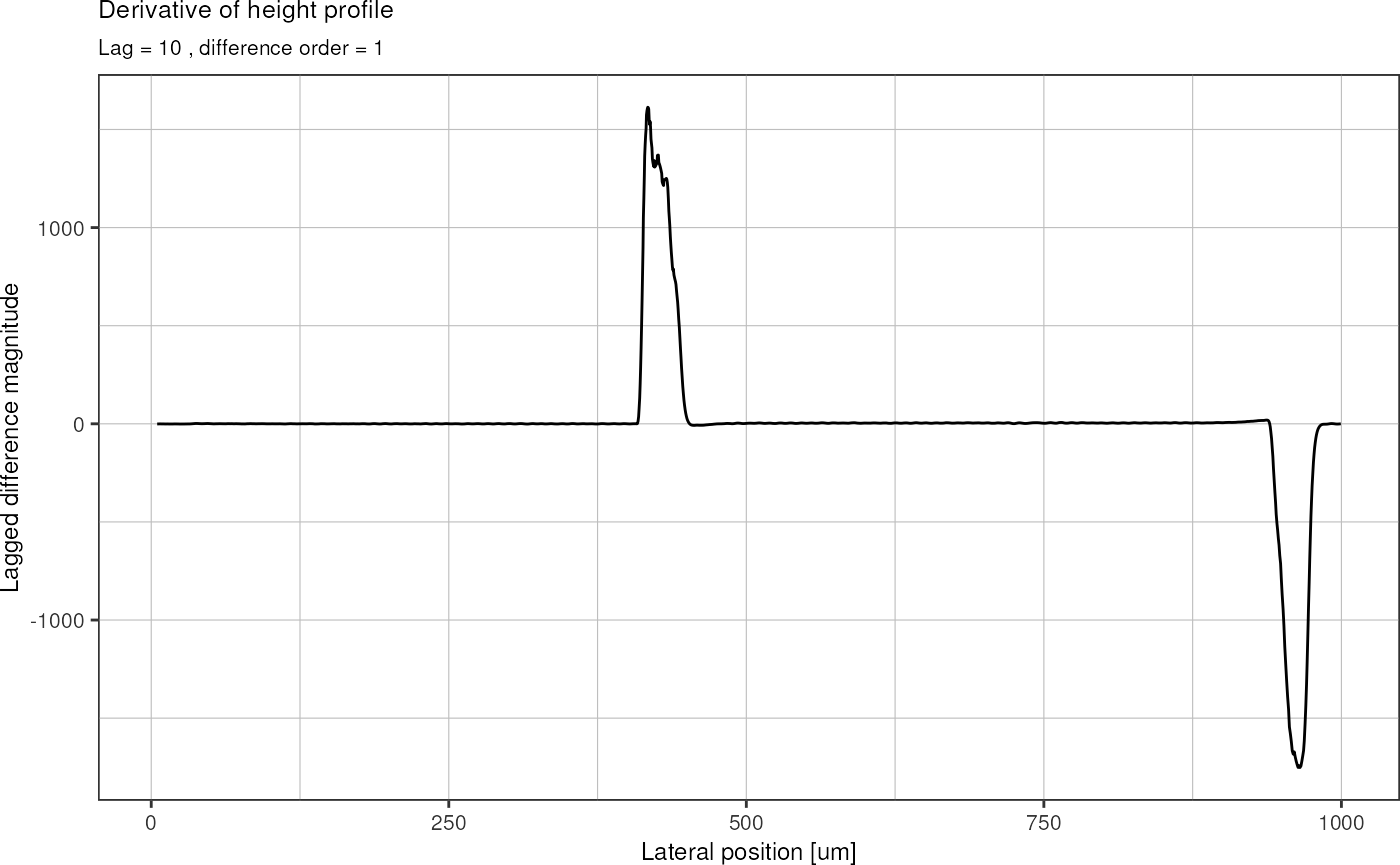
The lag parameter defines the sliding window size that
should be used for difference calculation and can be used to smooth the
resulting derivative plot. For the remainder of this analysis, I will
use lag = 10.
This function finds the index of the first edge of the height
profile, which should correspond to the edge of the first structure on
the wafer (left-to-right). The x coordinate where the derivative first
exceeds a give threshold minSlope is identified as an edge.
For this analysis I am using minSlope = 500.
get_index_first_peak <- function(values, minSlope) {
# find the first maximum
i <- 1
while (TRUE) {
if (values[i] > minSlope) {
return(i)
}
i <- i+1
}
}
get_index_first_peak(derivative$d_height, 500)
#> [1] 816Now above defined function can be used to determine the start and end coordinate of a profile. Using this information, the total length of a profile can be rescaled to cover 40.5 mm which is known from the initial AutoCAD design. This function detects the beginning and end of the height profile and then rescales the corresponding lateral position
rescale_profile <- function(profile, lag, minSlope) {
# calculate derivative of height w.r.t. position
dHeight <- diff(profile[["height"]], lag = lag) / diff(profile[["position"]], lag = lag)
# get index of first peak
first <- get_index_first_peak(dHeight, minSlope)
# get index of last peak
last <- get_index_first_peak(rev(dHeight)* (-1), minSlope)
# convert indices into corresponding position value
posFirst <- profile[["position"]][first + lag]
posLast <- rev(profile[["position"]])[last]
# rescale everything: distance between first and last position should be exactly 45mm
# discard data outside of the interval
profile[(first + lag):(nrow(profile)-last), ] %>%
mutate(position = seq(0, 40500, length.out = n())) %>%
return()
}A rescaled profile then looks like this. Note how the beginning and end are truncated, compared to the plot of the same trace shown above.
profileRescaled <- profile %>%
rescale_profile(lag = 10, minSlope = 500)
plot_heightprofile(profileRescaled)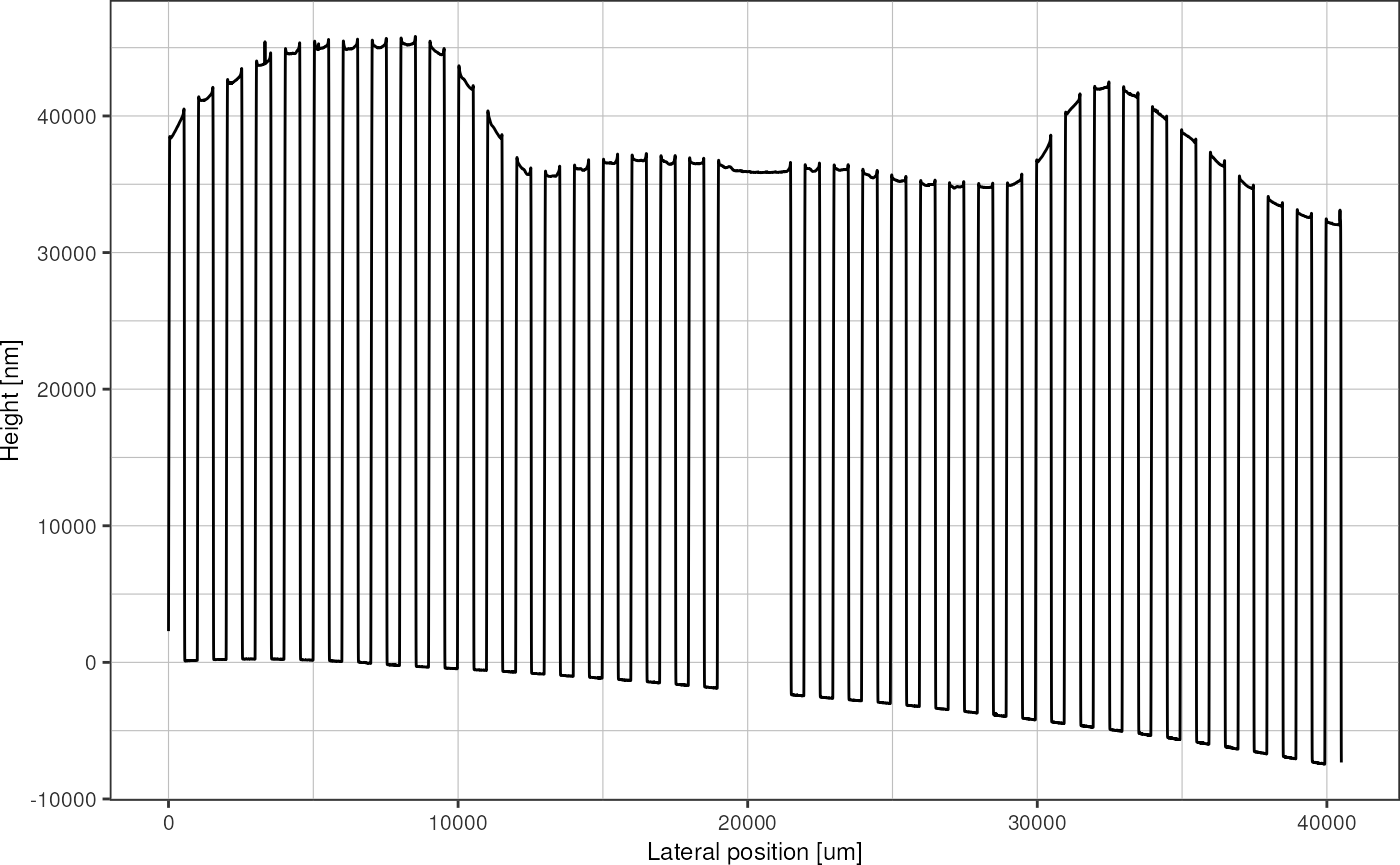
Next, the geometrical information known from the AutoCAD design can be used to identify the peaks and valleys present in the design. At the valleys, the height profile is then sampled at discrete points in order to capture the baseline shift. These discrete baseline points will later be used to fit a continuous baseline curve.
get_baseline_points <- function(profile) {
# sample points to capture the baseline
samplePoints <- seq(750, 40500, by = 1000)
# exclude center region (has no gap)
samplePoints <- samplePoints[samplePoints < 19000 | samplePoints > 21500]
xIndices <- sapply(samplePoints, function(x,y) which.min(abs(x-y)), profile[["position"]])
# return baseline points
tibble("position" = profile[["position"]][xIndices],
"height" = profile[["height"]][xIndices]) %>%
return()
}The sampled baseline data points look like this:
baselinePoints <- profileRescaled %>%
get_baseline_points()
baselinePoints
#> # A tibble: 38 × 2
#> position height
#> <dbl> <dbl>
#> 1 750. 126.
#> 2 1750. 206.
#> 3 2750. 246.
#> 4 3750. 236.
#> 5 4750. 174.
#> 6 5750. 92.9
#> 7 6750. -2.16
#> 8 7750. -151.
#> 9 8750. -310.
#> 10 9750. -436.
#> # … with 28 more rows
profileRescaled %>%
plot_heightprofile() +
geom_point(data = baselinePoints, shape = 23, color = "firebrick1")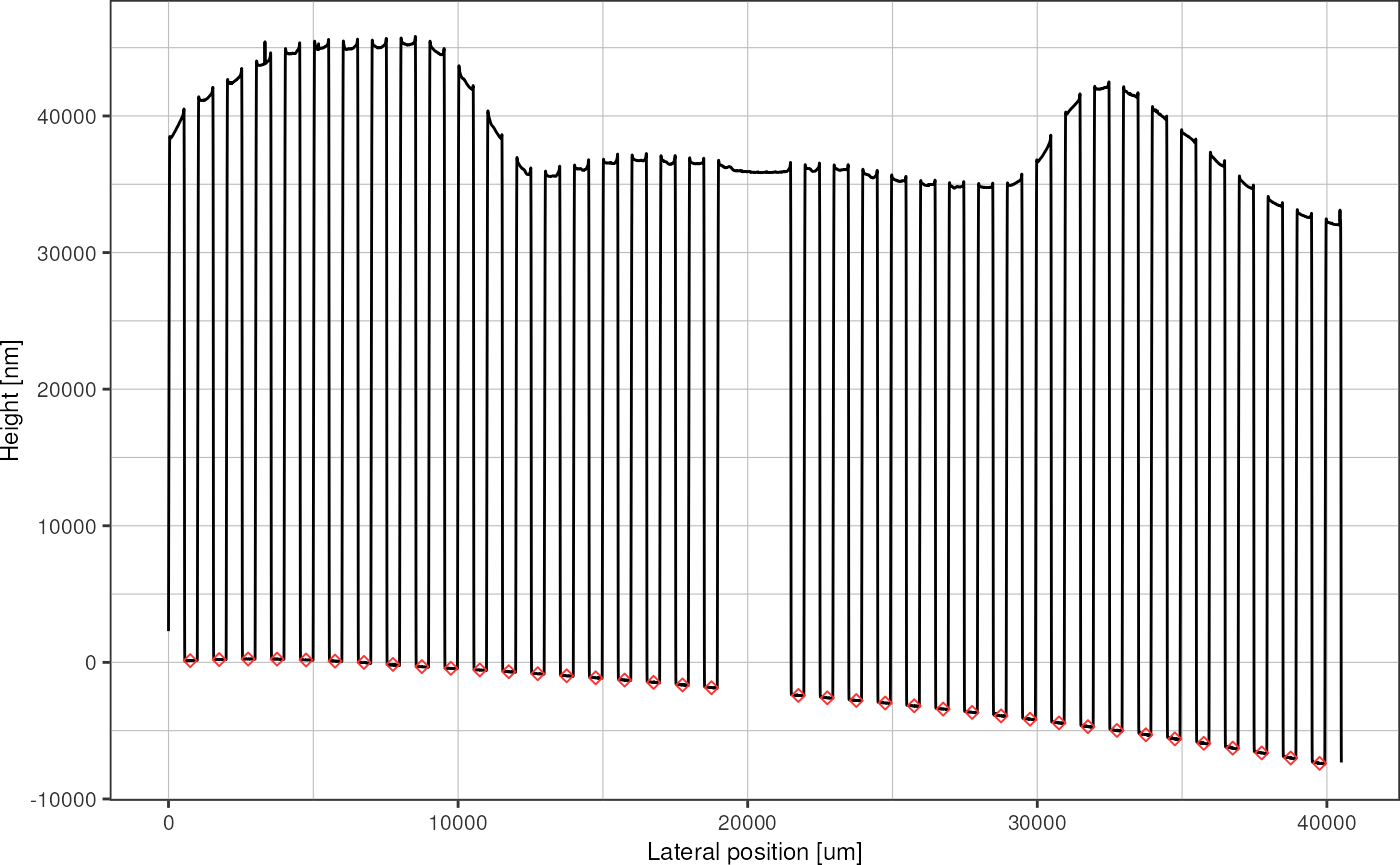
Use LOESS regression to fit curve to the baseline data points:
baseline_regression <- function(profile, baselinePoints, loessSpan) {
# LOESS regression to fit a function to the baseline data points
loessModel <- loess(height ~ position, data = baselinePoints, span = loessSpan)
# extrapolate
profile %>%
mutate("baseline" = predict(loessModel, position)) %>%
return()
}Regression of the baseline points looks like this:
profileRescaled %>%
baseline_regression(baselinePoints, loessSpan = 0.2) %>%
plot_heightprofile() +
geom_line(aes(y = baseline), color = "firebrick2")
#> Warning: Removed 3004 rows containing missing values (`geom_line()`).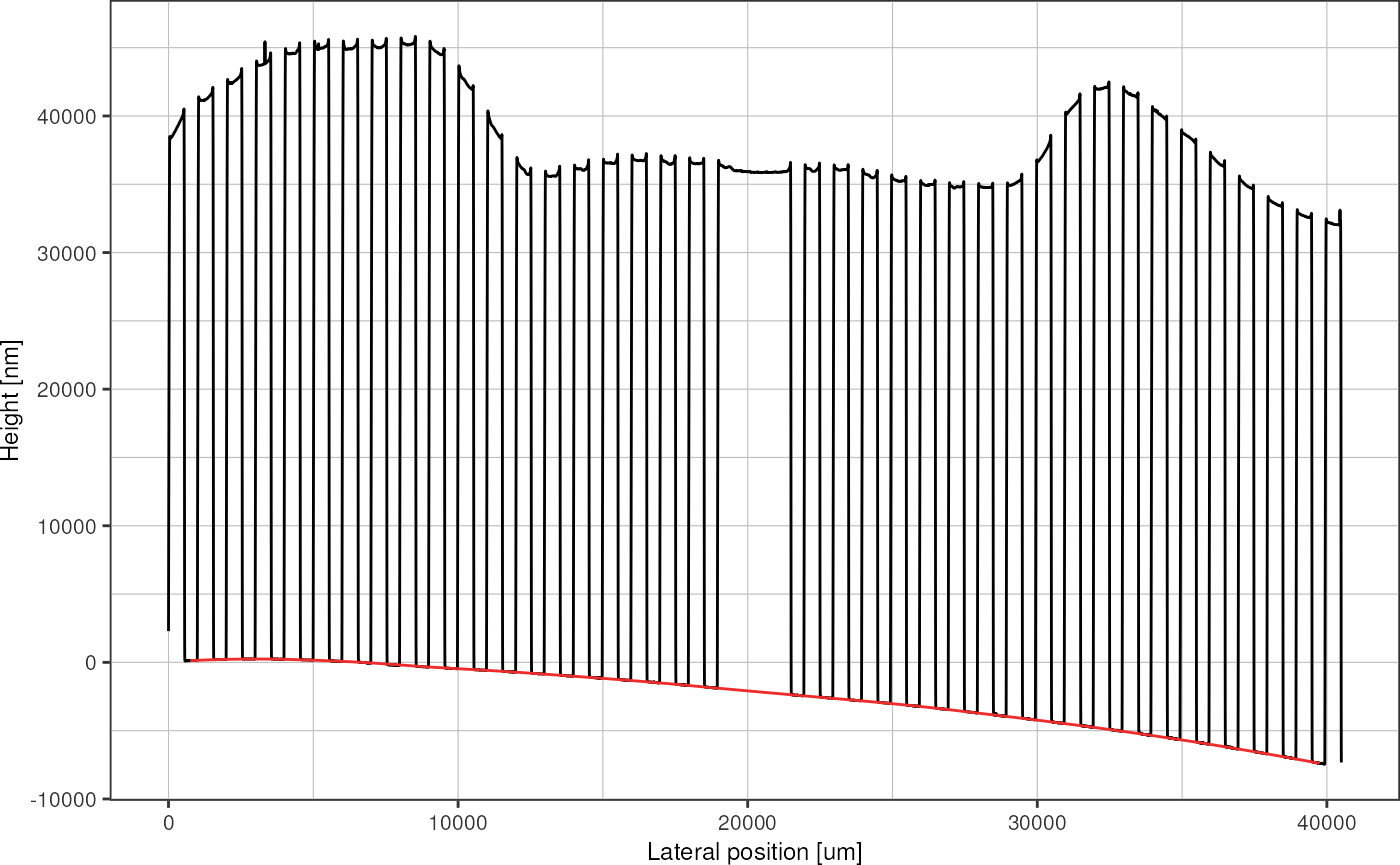
Note: loess regression doesn’t allow extrapolation, removes leftmost and rightmost data points.
The regression line can the be subtracted from the height data in order to level all the valleys to zero.
subtract_baseline <- function(profile) {
profile %>%
mutate(height = height - baseline) %>%
filter(!is.na(height)) %>%
select(!baseline) %>%
return()
}
profileRescaled %>%
baseline_regression(baselinePoints, loessSpan = 0.2) %>%
subtract_baseline() %>%
plot_heightprofile() 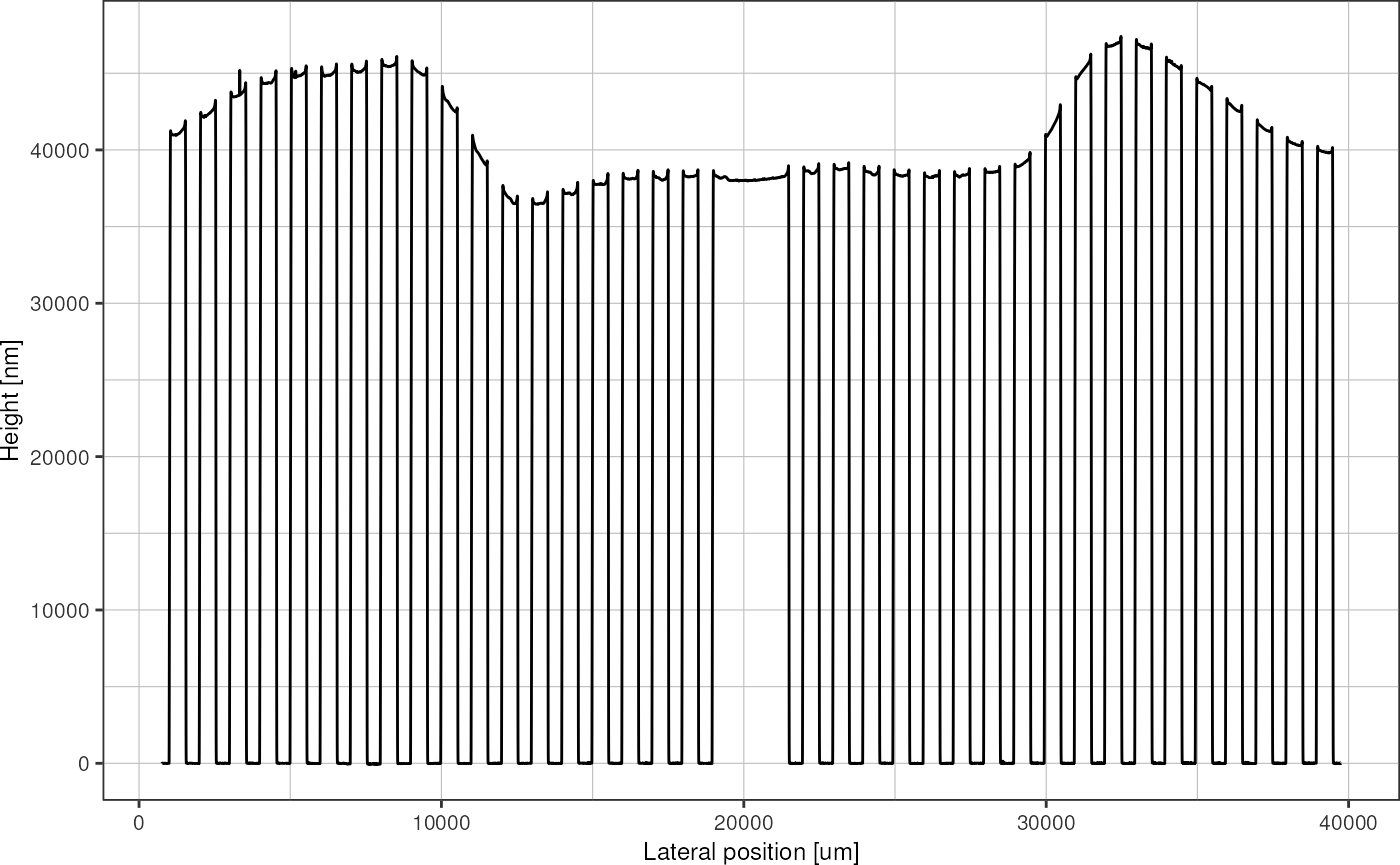
This function combines all the steps:
baseline_correction <- function(profile) {
# lag and minSlope are hardcoded in here!
rescaled <- profile %>%
rescale_profile(10, 500)
baselinePoints <- rescaled %>%
get_baseline_points()
rescaled %>%
baseline_regression(baselinePoints, 0.2) %>%
subtract_baseline() %>%
return()
}Iterate over all the traces and correct for baseline shift:
resultsCorrected <- tibble()
for (traceId in unique(results$id)) {
corrected <- results %>%
filter(id == traceId) %>%
baseline_correction()
resultsCorrected <- bind_rows(resultsCorrected, corrected)
}This function can be used to plot the baseline-corrected profiles for every wafer:
p <- plot_heightprofile_bywafer(resultsCorrected)
print(p)
As can be seen in this overview plot, the baseline correction method seems to work for all the profiles.
post-processing
The next step in the analysis is to summarize the duplicate measurements that exist for every structure, and interpolate the height profile across the gaps, in order to obtain a comprehensive plot that describes the spin coating thickness as a function of the radial distance from the wafer center, as well as RPM and spin time.
Function that removes the baseline segments of the data using the known locations of valleys in the structure, and interpolating those values from the surrounding data:
# Geometrically, a valley is 500 um wide. Set to a larger value than that to filter out overshoots in the signal at the edges
interpolate_valleys <- function(profile, width = 650) {
## 1. remove gap data
# the baseline centers are supposed to be located right in the middle of the valleys
baselineCenters <- seq(-250, 42000, by = 1000)
# exclude middle region
# baselineCenters <- baselineCenters[baselineCenters < 19000 | baselineCenters > 21500]
baselinePositions <- sapply(baselineCenters, function(x) seq(x-0.5*width, x + 0.5*width)) %>%
as.numeric()
positionsRounded <- round(profile[["position"]])
idx <- !positionsRounded %in% baselinePositions
positions <- profile$position[idx]
height <- profile$height[idx]
## 2. interpolate between gaps
a <- approx(positions, height, profile$position)
profile %>%
mutate(height = a$y) %>%
filter(!is.na(height)) %>%
return()
}The resulting height profile does not contain gaps anymore:
resultsCorrected %>%
filter(id == "00_job9945_eastwest.csv") %>%
interpolate_valleys() %>%
plot_heightprofile() +
ylim(c(0, 50000))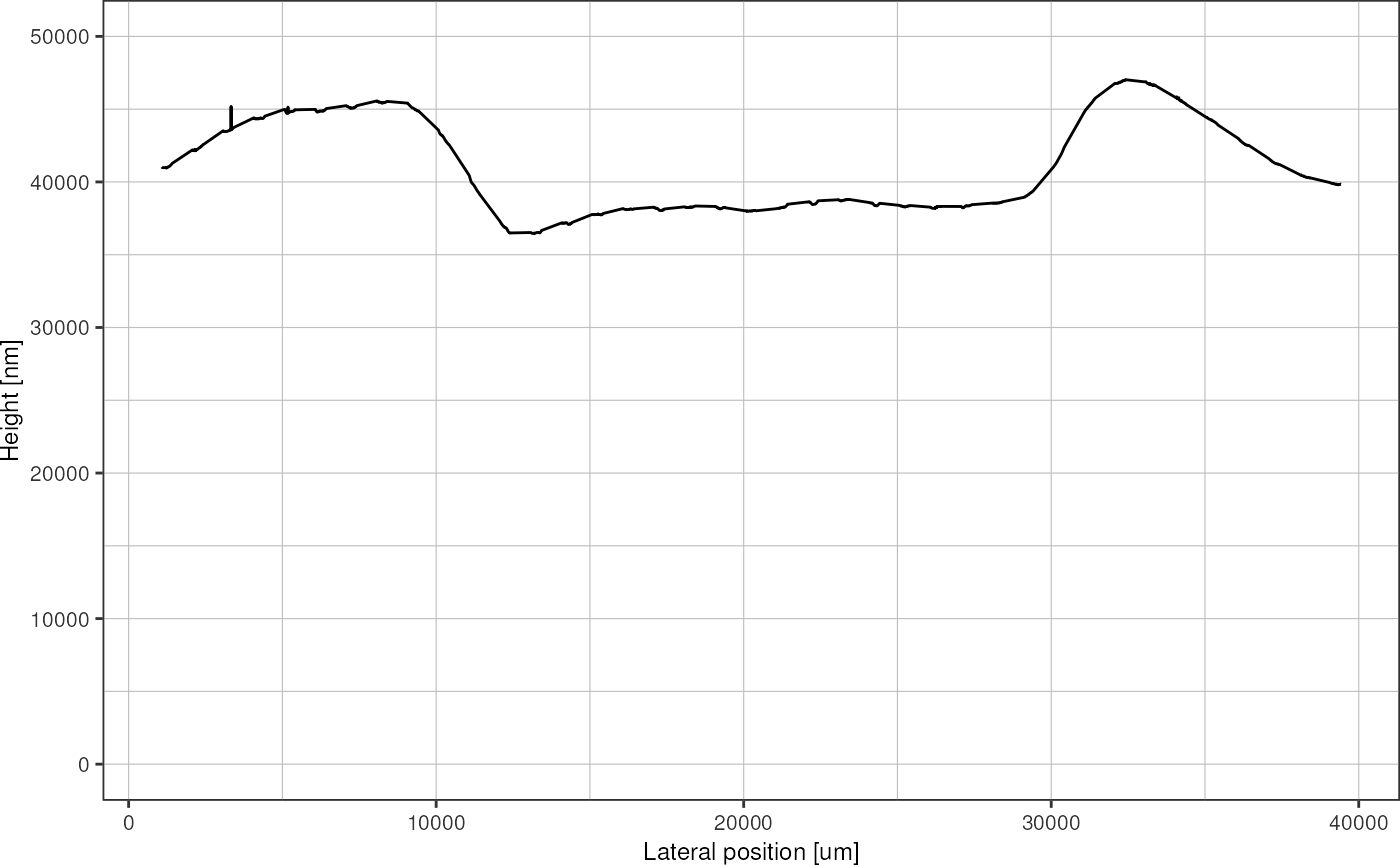
Do this for all traces and show them in a single plot:
resultsInterpolated <- tibble()
for (traceId in unique(resultsCorrected$id)) {
r <- resultsCorrected %>%
filter(id == traceId) %>%
interpolate_valleys()
resultsInterpolated <- bind_rows(resultsInterpolated, r)
}
ggplot(resultsInterpolated, aes(x = position, y = height, color = direction)) +
geom_line() +
geom_hline(yintercept = 0) +
facet_wrap(~ wafer) +
theme_pretty() +
labs(x = "Lateral position [um]",
y = "Height [nm]",
color = "Trace")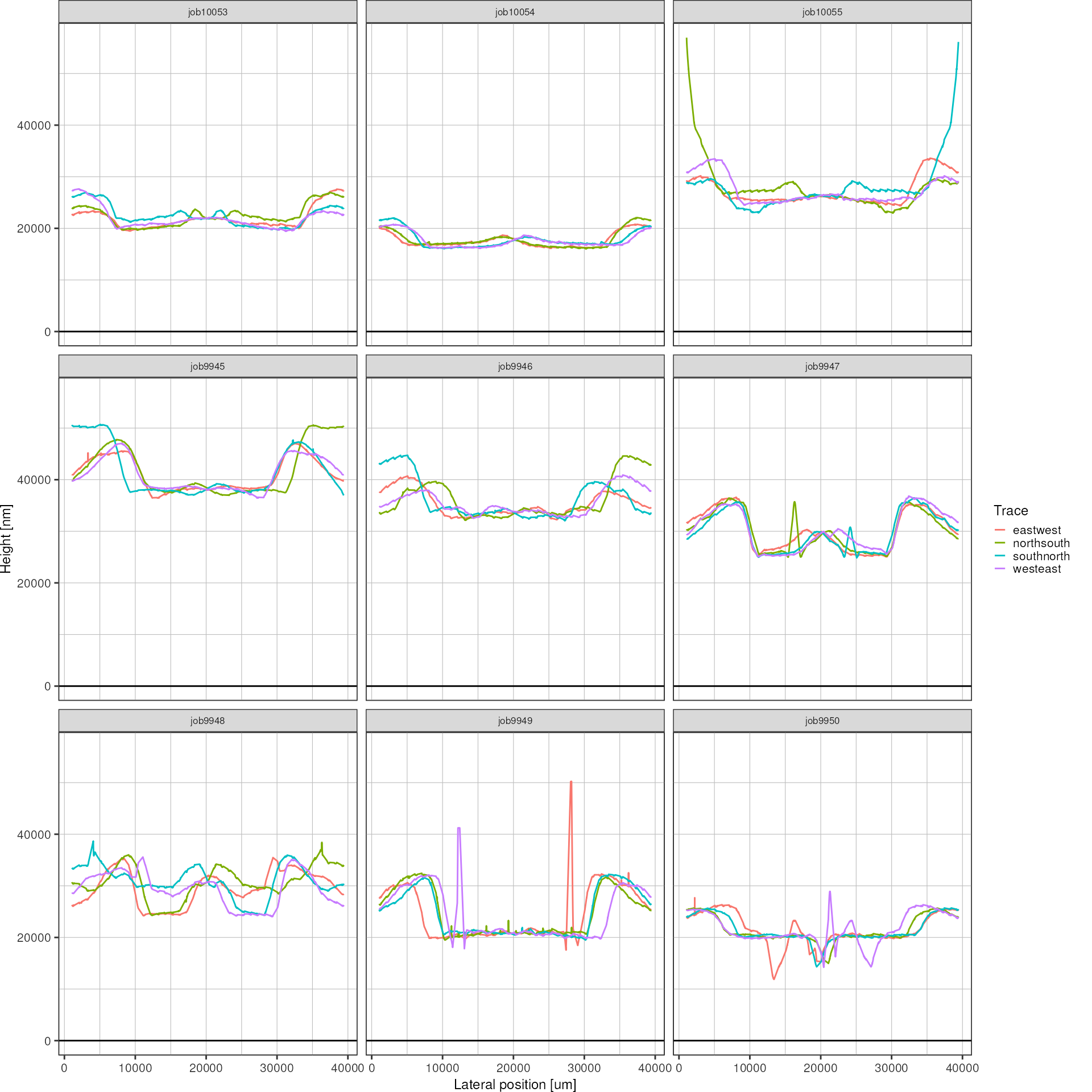
For each wafer, four traces were measured, of which pairs of two should be identical to each other: trace south-north measures the same structure as north-south, and the same is true for traces east-west and west-east. In above graph, this similarity is not obvious, because the measurement directions are reversed (west-east goes left-to-right and east-west the other way around). Therefore, two of the four traces have to be reversed, so that the only measurement directions are top-to-bottom and left-to-right. Furthermore, the data will be centered around zero, so that the origin is located in the wafer center.
mirror_and_center <- function(resultsInterpolated) {
resultsInterpolated %>%
group_by(wafer, direction) %>%
arrange(position, .by_group = TRUE) %>%
mutate(height = case_when(direction %in% c("southnorth", "eastwest") ~ rev(height),
TRUE ~ height)) %>%
# center around zero
mutate(position = position - 0.5 * max(position)) %>%
ungroup() %>%
return()
}Now there is a lot more similarity going on in the height profiles. Of the four traces, those in horizontal and vertical direction, respectively, should be overlapping to a large degree.
heights <- resultsInterpolated %>%
mirror_and_center()
ggplot(heights, aes(x = position, y = height, color = direction)) +
geom_line() +
geom_hline(yintercept = 0) +
facet_wrap(~ wafer) +
theme_pretty() +
labs(x = "Lateral position [um]",
y = "Height [nm]",
color = "Trace")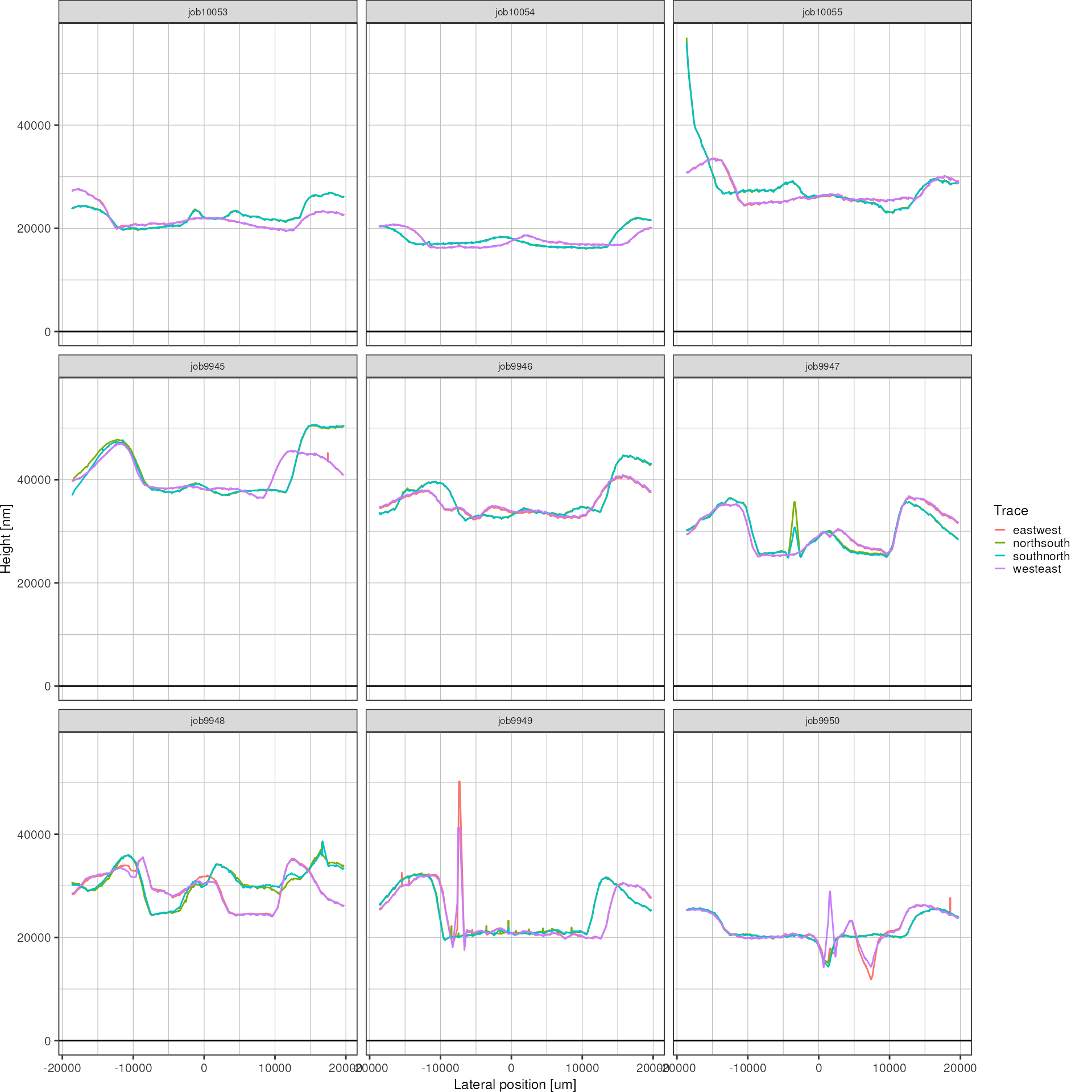
For a single wafer:
heights %>%
filter(wafer == "job9946") %>%
ggplot(aes(x = position, y = height, color = direction)) +
geom_line() +
geom_hline(yintercept = 0) +
theme_pretty() +
labs(x = "Position from wafer center [um]",
y = "Height [nm]",
color = "Trace direction")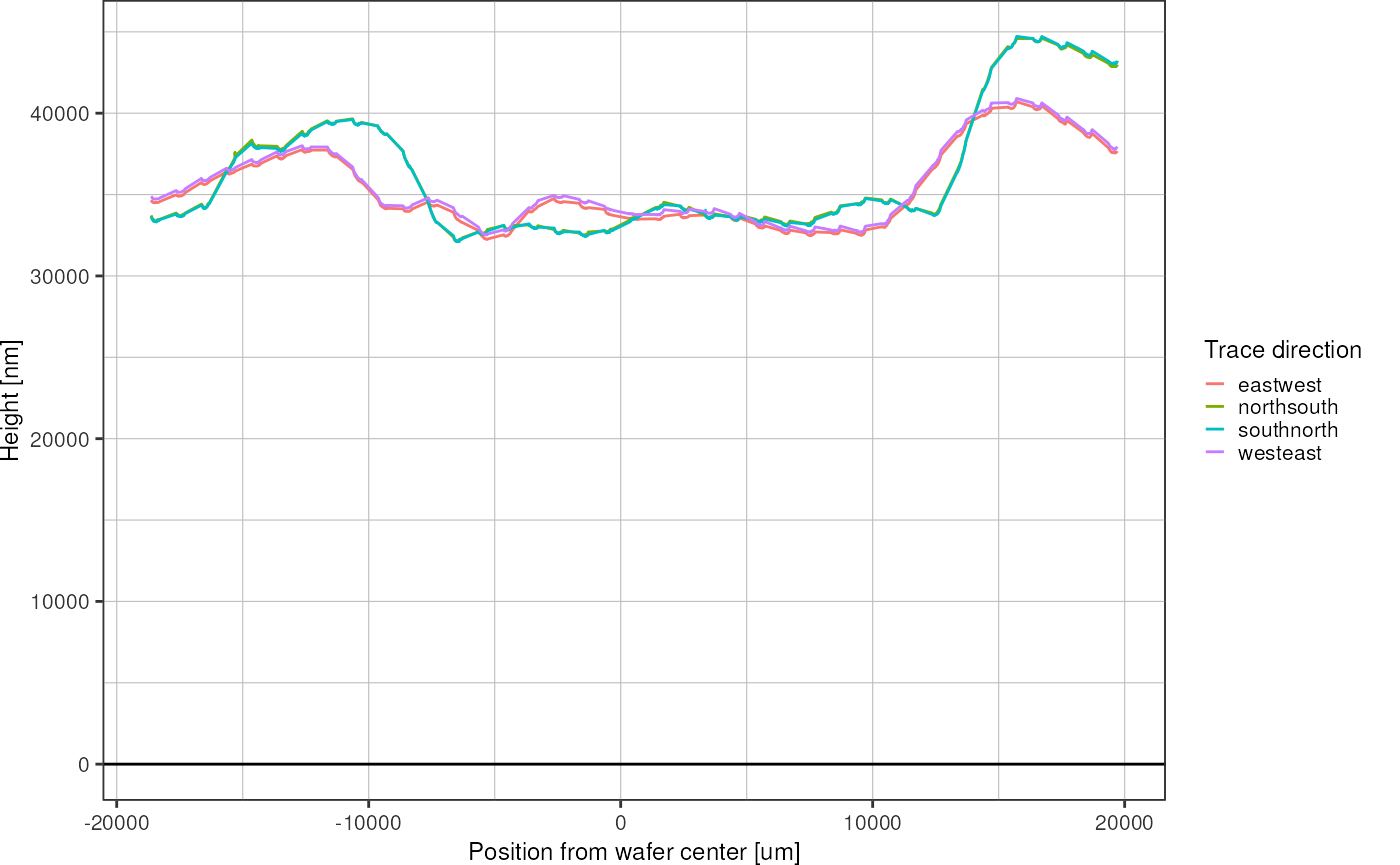
The duplicate measurements of the horizontal and vertical structure will be averaged.
average_duplicate_traces <- function(heights) {
heights %>%
mutate(position = round(position)) %>%
group_by(rpm, wafer, spintime, orientation, position) %>%
summarise(height = round(mean(height)),
height_sd = sd(height),
.groups = "drop") %>%
return()
}
heights <- heights %>%
average_duplicate_traces()
heights %>%
ggplot(aes(x = position, y = height, color = orientation)) +
geom_line() +
geom_hline(yintercept = 0) +
theme_pretty() +
labs(x = "Position from wafer center [um]",
y = "Height [nm]",
color = "Trace direction") +
facet_wrap(~ wafer)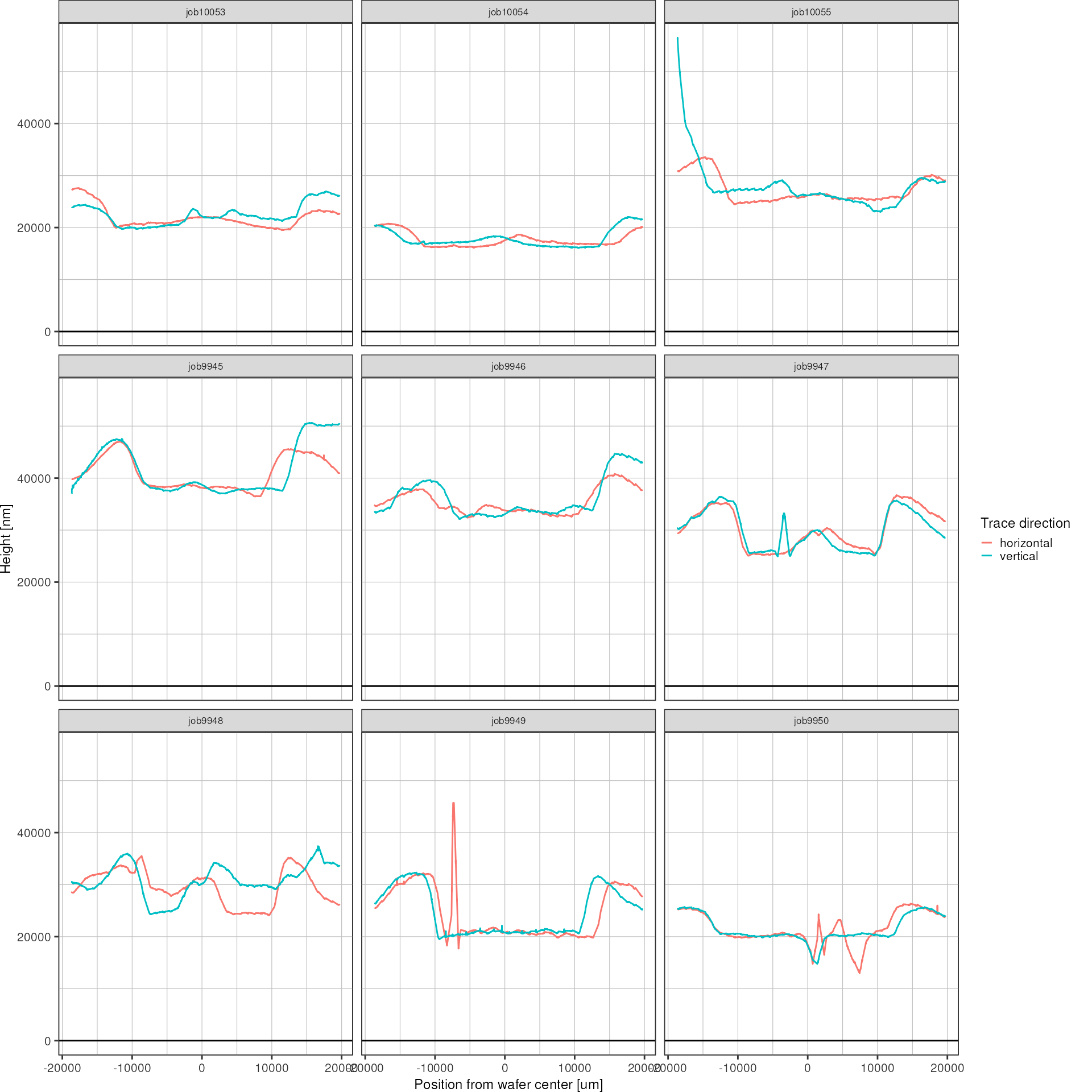
Finally, since the spin coating process should be radially symmetrical more or less (ideally), I want to describe the height profile as a function of the radial distance from the wafer center. To that end, data with negative position coordinate will be flipped over into the positive range.
 { width=50% }
{ width=50% }
make_radial <- function(heights) {
heights %>%
mutate(quadrant = case_when(orientation == "vertical" & position < 0 ~ "south",
orientation == "vertical" & position >= 0 ~ "north",
orientation == "horizontal" & position < 0 ~ "west",
orientation == "horizontal" & position >= 0 ~ "east",
TRUE ~ "ERROR")) %>%
# flip values with negative position coordinate into positive range
mutate(position = case_when(position < 0 ~ -position,
TRUE ~ position)) %>%
ungroup() %>%
return()
}
heightsRadial <- heights %>%
make_radial()
ggplot(heightsRadial, aes(x = position, y = height, color = quadrant)) +
geom_line() +
geom_hline(yintercept = 0) +
facet_wrap(~ wafer) +
theme_pretty() +
labs(x = "Distance from wafer center [um]",
y = "Height [nm]",
color = "Quadrant")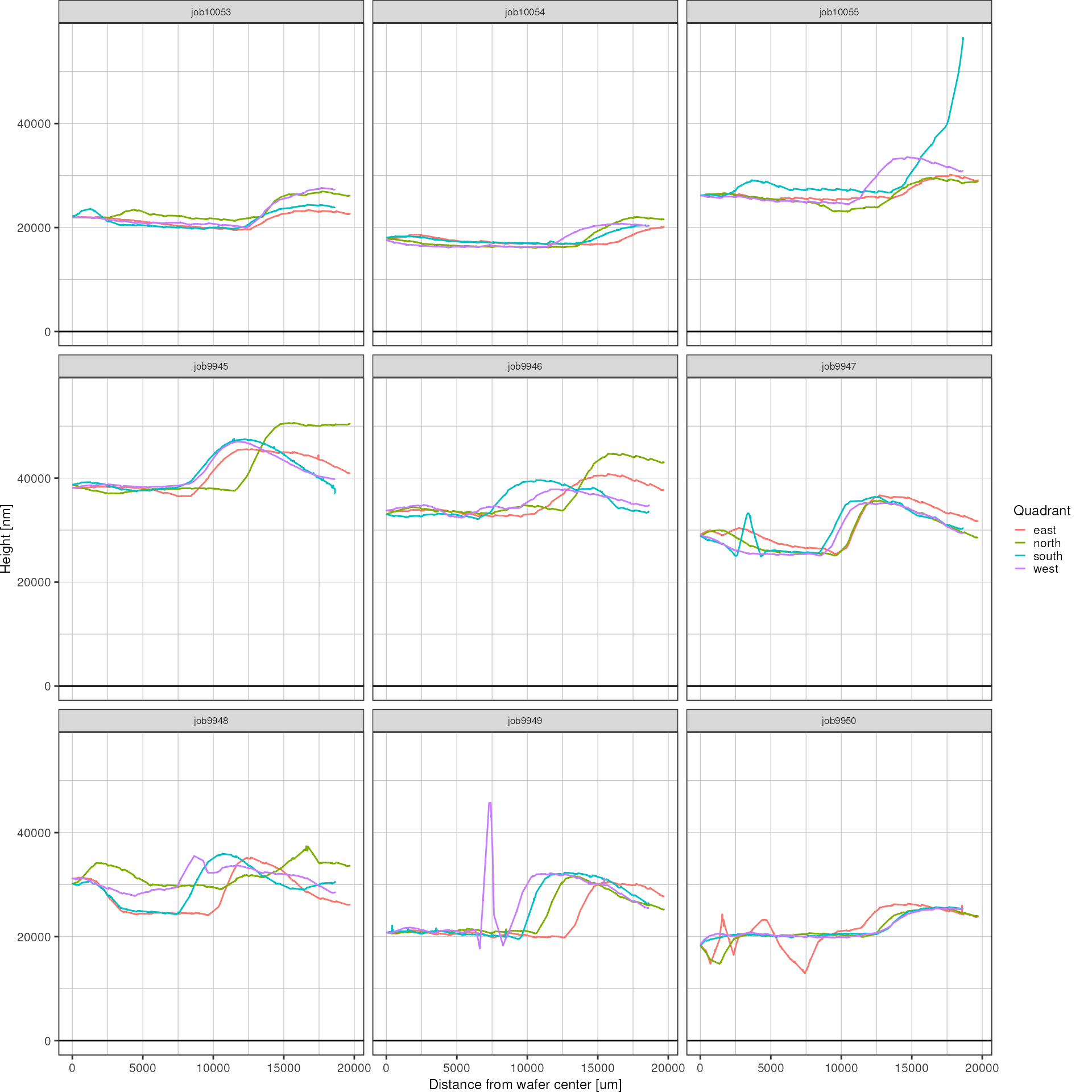
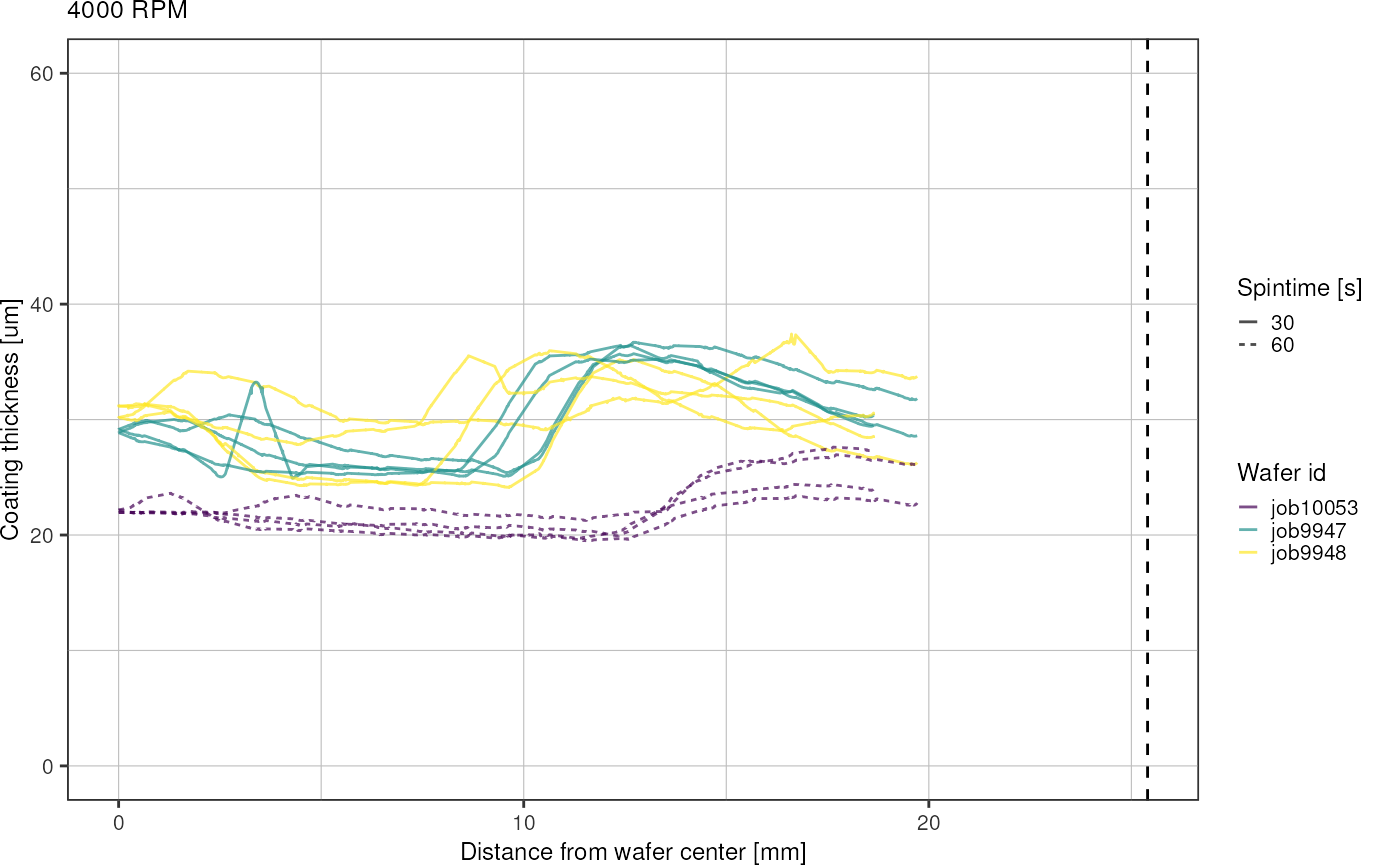
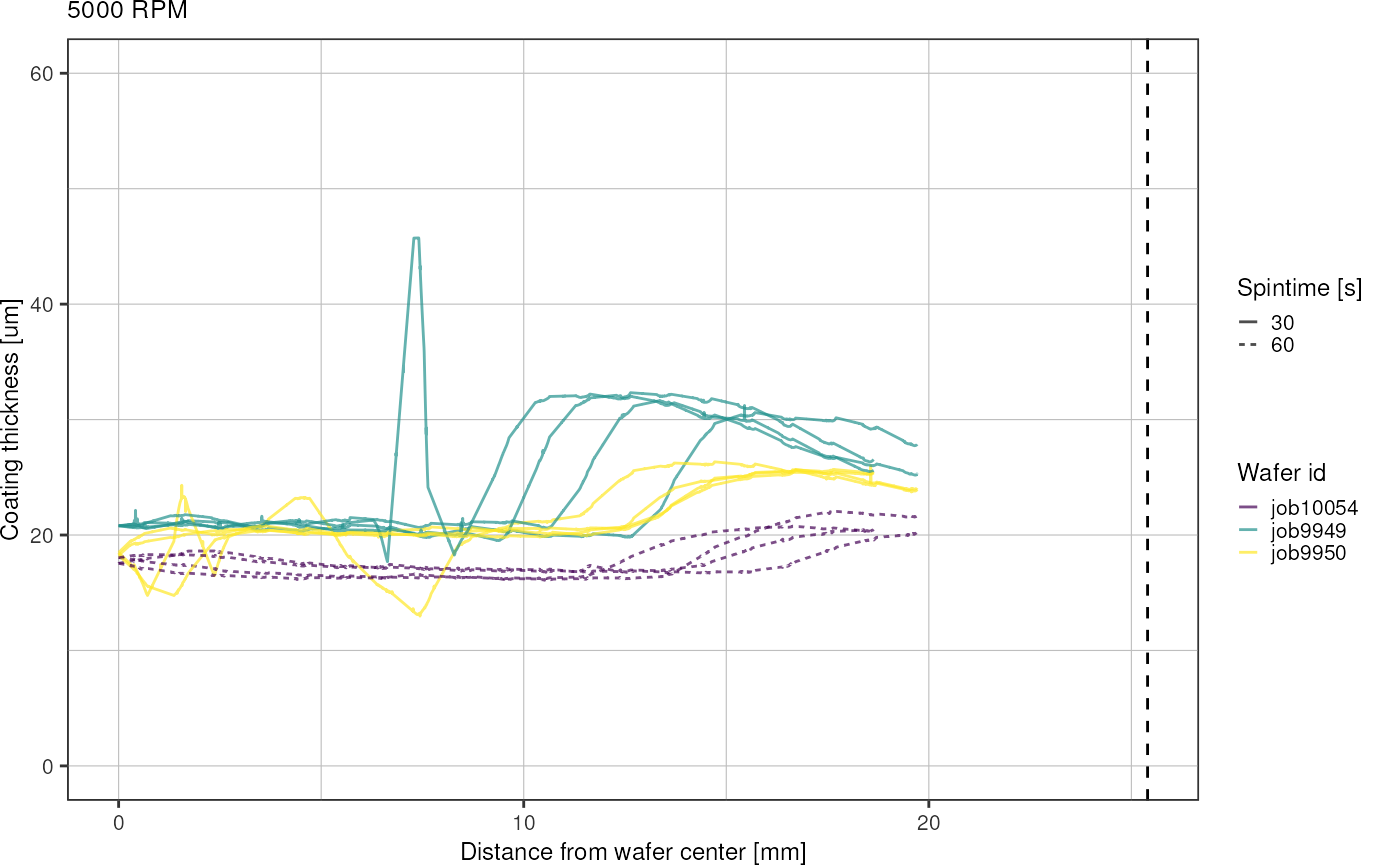
Plot by RPM and spintime:
for (r in unique(heightsRadial$rpm)) {
p <- heightsRadial %>%
filter(rpm == r) %>%
ggplot(aes(x = position*1e-3, y = height*1e-3, color = wafer)) +
geom_vline(xintercept = 25.4, linetype = "dashed") +
geom_line(aes(group = interaction(wafer, quadrant), linetype = factor(spintime)), size = 0.5, alpha = 0.7) +
labs(x = "Distance from wafer center [mm]",
y = "Coating thickness [um]",
linetype = "Spintime [s]",
color = "Wafer id",
title = paste(r, "RPM")) +
scale_color_viridis_d() +
theme_pretty() +
ylim(c(0, 60))
print(p)
}
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.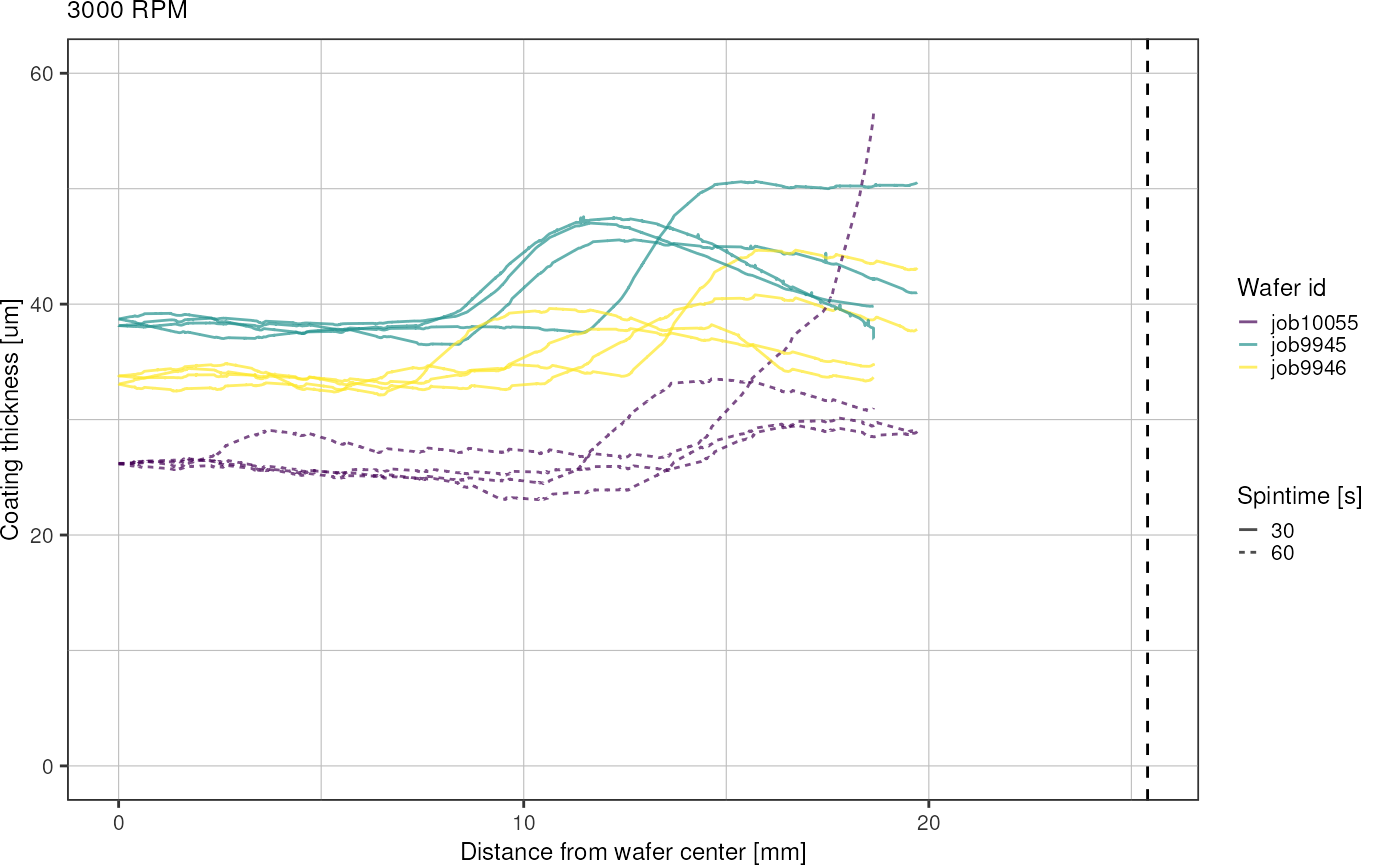
conclusions
- spin coating results in circular inner region of uniform thickness and outer rim with thicker coating
- spinning for longer time (60 instead of 30 s) seems to expand the inner region
- higher variation in thickness across wafers for lower RPM (3000, 4000)
- place chip designs radially symmetrical on the wafer to increase uniformness